
EXT2与EXT3区别
Linux之前缺省情况下使用的文件系统为Ext2,ext2文件系统的确高效稳定。但是,随着Linux系统在关键业务中的应用,Linux文件系统的弱点也渐渐显露出来了:其中系统缺省使用的ext2文件系统是非日志文件系统。这在关键行业的应用是一个致命的弱点,Ext3文件系统是直接从Ext2文件系统发展而来,目前ext3文件系统已经非常稳定可靠。它完全兼容ext2文件系统。用户可以平滑地过渡到一个日志功能健全的文件系统中来。这实际上了也是ext3日志文件系统初始设计的初衷。
1) ext3和ext2的主要区别在于,ext3引入Journal(日志)机制,Linux内核从2.4.15开始支持ext3,它是从文件系统过渡到日志式文件系统最为简单的一种选择,ext3提供了数据完整性和可用性保证。
2) ext2和ext3的格式完全相同,只是在ext3硬盘最后面有一部分空间用来存放Journal的记录;
3) 在ext2中,写文件到硬盘中时,先将文件写入缓存中,当缓存写满时才会写入硬盘中;
4) 在ext3中,写文件到硬盘中时,先将文件写入缓存中,待缓存写满时系统先通知Journal,再将文件写入硬盘,完成后再通知Journal,资料已完成写入工作;
5) 在ext3中,也就是有Journal机制里,系统开机时检查Journal的内容,来查看是否有错误产生,这样就加快了开机速度;
EXT3日志文件系统的特点
系统使用了ext3文件系统后,即使在非正常关机后,系统也不需要检查文件系统。宕机发生后,恢复ext3文件系统的时间只要数十秒钟。
ext3文件系统能够极大地提高文件系统的完整性,避免了意外宕机对文件系统的破坏。在保证数据完整性方面,ext3文件系统有2种模式可供选择。其中之一就是"同时保持文件系统及数据的一致性"模式。采用这种方式,你永远不再会看到由于非正常关机而存储在磁盘上的垃圾文件。
尽管使用ext3文件系统时,有时在存储数据时可能要多次写数据,但是,从总体上看来,ext3比ext2的性能还要好一些。这是因为ext3的日志功能对磁盘的驱动器读写头进行了优化。所以,文件系统的读写性能较之Ext2文件系统并来说,性能并没有降低。
由ext2文件系统转换成ext3文件系统非常容易,只要简单地键入两条命令即可完成整个转换过程,用户不用花时间备份、恢复、格式化分区等。用一个ext3文件系统提供的小工具tune2fs,它可以将ext2文件系统轻松转换为ext3日志文件系统。另外,ext3文件系统可以不经任何更改,而直接加载成为ext2文件系统。
Ext3有多种日志模式,一种工作模式是对所有的文件数据及metadata(定义文件系统中数据的数据,即数据的数据)进行日志记录(data=journal模式);另一种工作模式则是只对metadata记录日志,而不对数据进行日志记录,也即所谓data=ordered或data=writeback模式。系统管理人员可以根据系统的实际工作要求,在系统的工作速度与文件数据的一致性之间作出选择。
EXT3的优点
为什么你需要从ext2迁移到ext3呢?以下有四个主要原因:可用性、数据完整性、速度、易于迁移。
在非正常当机后(停电、系统崩溃),只有在通过e2fsck进行一致性校验后,ext2文件系统才能被装载使用。运行e2fsck的时间主要取决于 ext2文件系统的大小。校验稍大一些的文件系统(几十GB)需要很长时间。如果文件系统上的文件数量多,校验的时间则更长。校验几百个GB的文件系统可能需要一个小时或更长。这极大地限制了可用性。相比之下,除非发生硬件故障,即使非正常关机,ext3也不需要文件系统校验。这是因为数据是以文件系统始终保持一致方式写入磁盘的。在非正常关机后,恢复ext3文件系统的时间不依赖于文件系统的大小或文件数量,而依赖于维护一致性所需"日志"的大小。使用缺省日志设置,恢复时间仅需一秒(依赖于硬件速度)。
使用ext3文件系统,在非正常关机时,数据完整性能得到可靠的保障。你可以选择数据保护的类型和级别。你可以选择保证文件系统一致,但是允许文件系统上的数据在非正常关机时受损;这是可以在某些状况下提高一些速度(但非所有状况)。你也可以选择保持数据的可靠性与文件系统一致;这意味着在当机后,你不会在新近写入的文件中看到任何数据垃圾。这个保持数据的可靠性与文件系统一致的安全的选择是缺省设置。
尽管ext3写入数据的次数多于ext2,但是ext3常常快于ext2(高数据流)。这是因为ext3的日志功能优化硬盘磁头的转动。你可以从3种日志模式中选择1种来优化速度,有选择地牺牲一些数据完整性。
你可以不重新格式化硬盘,并且很方便的从ext2迁移至ext3而享受可靠的日志文件系统的好处。对,不需要做长时间的、枯燥的、有可能失误的"备份-重新格式化-恢复"操作,就可以体验ext3的优点。有两种迁移的方法:如果你升级你的系统,Red Hat Linux安装程序会协助迁移。需要你做的工作 就是为每一个文件系统按一下选择按钮。使用tune2fs程序可以为现存的ext2文件系统增加日志功能。如果文件系统在转换的过程已经被装载了(mount),那么在root目录下会出现文件".journal";如果文件系统没有被装载,那么文件系统中不会出现该文件。转换文件系统,只需要运行tune2fs –j /dev/hda1(或者你要转换的文件系统所在的任何设备名称),同时把文件/etc/fstab中的ext2修改为ext3。如果你要转换自己的根文件系统,你必须使用initrd引导启动。参照mkinitrd的手册描述运行程序,同时确认自己的LILO或GRUB配置中装载了initrd(如果没有成功,系统仍然能启动,但是根文件系统会以ext2形式装载,而不是ext3,你可以使用命令cat /proc/mounts 来确认这一点。)详情可参看tune2fs命令的man page在线手册(执行man tune2fs)。
ext3日志文件系统是目前linux系统由ext2文件系统过度到日志文件系统最为简单的一种选择,实现方式也最为简洁。由于是直接从ext2文件系统发展而来,系统由ext2文件系统过渡到ext3日志文件系统升级过程平滑,可以最大限度地保证系统数据的安全性。目前linux系统要使用日志文件系统,最保险的方式就是选择ext3文件系统。
EXT3与EXT4的主要区别
Linux kernel自2.6.28开始正式支持新的文件系统 Ext4。 Ext4是Ext3的改进版,修改了Ext3中部分重要的数据结构,而不仅仅像Ext3对Ext2那样,只是增加了一个日志功能而已。Ext4 可以提供更佳的性能和可靠性,还有更为丰富的功能:
执行若干条命令,就能从Ext3在线迁移到Ext4,而无须重新格式化磁盘或重新安装系统。原有Ext3数据结构照样保留,Ext4作用于新数据,当然,整个文件系统因此也就获得了Ext4所支持的更大容量。
较之Ext3目前所支持的最大16TB文件系统和最大2TB文件,Ext4分别支持1EB(1,048,576TB,1EB=1024PB,1PB=1024TB)的文件系统,以及16TB 的文件。
Ext3目前只支持32,000个子目录,而Ext4支持无限数量的子目录。
Ext3采用间接块映射,当操作大文件时,效率极其低下。比如一个 100MB 大小的文件,在Ext3中要建立25,600个数据块(每个数据块大小为 4KB)的映射表。而Ext4引入了现代文件系统中流行的extents概念,每个 extent 为一组连续的数据块,上述文件则表示为"该文件数据保存在接下来的25,600个数据块中",提高了不少效率。
当写入数据到 Ext3 文件系统中时,Ext3 的数据块分配器每次只能分配一个 4KB 的块,写一个 100MB 文件就要调用 25,600 次数据块分配器,而 Ext4 的多块分配器"multiblock allocator"(mballoc) 支持一次调用分配多个数据块。
Ext3的数据块分配策略是尽快分配,而 Ext4 和其它现代文件操作系统的策略是尽可能地延迟分配,直到文件在 cache 中写完才开始分配数据块并写入磁盘,这样就能优化整个文件的数据块分配,与前两种特性搭配起来可以显著提升性能。
以前执行 fsck 第一步就会很慢,因为它要检查所有的 inode,现在 Ext4 给每个组的 inode 表中都添加了一份未使用 inode 的列表,今后 fsck Ext4 文件系统就可以跳过它们而只去检查那些在用的 inode 了。
日志是最常用的部分,也极易导致磁盘硬件故障,而从损坏的日志中恢复数据会导致更多的数据损坏。Ext4的日志校验功能可以很方便地判断日志数据是否损坏,而且它将Ext3 的两阶段日志机制合并成一个阶段,在增加安全性的同时提高了性能。
日志总归有一些开销,Ext4允许关闭日志,以便某些有特殊需求的用户可以借此提升性能。
尽管延迟分配、多块分配和extents能有效减少文件系统碎片,但碎片还是不可避免会产生。Ext4支持在线碎片整理,并将提供e4defrag工具进行个别文件或整个文件系统的碎片整理。
Ext4支持更大的inode,较之Ext3默认的inode大小128字节,Ext4为了在 inode 中容纳更多的扩展属性(如纳秒时间戳或inode版本),默认inode大小为256字节。Ext4 还支持快速扩展属性(fast extended attributes)和inode保留(inodes reservation)。
12)持久预分配(Persistent preallocation)
P2P软件为了保证下载文件有足够的空间存放,常常会预先创建一个与所下载文件大小相同的空文件,以免未来的数小时或数天之内磁盘空间不足导致下载失败。 Ext4在文件系统层面实现了持久预分配并提供相应的API(libc 中的 posix_fallocate()),比应用软件自己实现更有效率。
磁盘上配有内部缓存,以便重新调整批量数据的写操作顺序,优化写入性能,因此文件系统必须在日志数据写入磁盘之后才能写commit记录,若commit 记录写入在先,而日志有可能损坏,那么就会影响数据完整性。Ext4默认启用barrier,只有当barrier之前的数据全部写入磁盘,才能写barrier之后的数据。(可通过"mount -o barrier=0″命令禁用该特性。)
XFS
XFS文件系统是SGI开发的高级日志文件系统,XFS极具伸缩性,非常健壮。所幸的是SGI将其移植到了Linux系统中。在linux环境下。目前版本可用的最新XFS文件系统的为1.2版本,可以很好地工作在2.4核心下。
XFS 是 Silicon Graphics,Inc. 于 90 年代初开发的。它至今仍作为 SGI 基于 IRIX 的产品(从工作站到超级计算机)的底层文件系统来使用。现在,XFS 也可以用于 Linux。XFS 的 Linux 版的到来是激动人心的,首先因为它为 Linux 社区提供了一种健壮的、优秀的以及功能丰富的文件系统,并且这种文件系统所具有的可伸缩性能够满足最苛刻的存储需求。
采用XFS文件系统,当意想不到的宕机发生后,首先,由于文件系统开启了日志功能,所以你磁盘上的文件不再会意外宕机而遭到破坏了。不论目前文件系统上存储的文件与数据有多少,文件系统都可以根据所记录的日志在很短的时间内迅速恢复磁盘文件内容。
XFS文件系统采用优化算法,日志记录对整体文件操作影响非常小。XFS查询与分配存储空间非常快。xfs文件系统能连续提供快速的反应时间。笔者曾经对XFS、JFS、Ext3、ReiserFS文件系统进行过测试,XFS文件文件系统的性能表现相当出众。
XFS 是一个全64-bit的文件系统,它可以支持上百万T字节的存储空间。对特大文件及小尺寸文件的支持都表现出众,支持特大数量的目录。最大可支持的文件大 小为263 = 9 x 1018 = 9 exabytes,最大文件系统尺寸为18 exabytes。
XFS使用高的表结构(B+树),保证了文件系统可以快速搜索与快速空间分配。XFS能够持续提供高速操作,文件系统的性能不受目录中目录及文件数量的限制。
XFS 能以接近裸设备I/O的性能存储数据。在单个文件系统的测试中,其吞吐量最高可达7GB每秒,对单个文件的读写操作,其吞吐量可达4GB每秒。
(1)最多只能支持32TB的文件系统和2TB的文件,实际只能容纳2TB的文件系统和16GB的文件
(3)Ext3文件系统使用32位空间记录块数量和i-节点数量
(4)当数据写入到Ext3文件系统中时,Ext3的数据块分配器每次只能分配一个4KB的块
EXT4是Linux系统下的日志文件系统,是EXT3文件系统的后继版本。
(1)Ext4的文件系统容量达到1EB,而文件容量则达到16TB
(3)Ext4文件系统使用64位空间记录块数量和i-节点数量
(3) 是一个全64-bit的文件系统,它可以支持上百万T字节的存储空间
主引导记录,是传统的分区机制,应用于绝大多数使用BIOS的PC设备
MBR只支持不超过2T的硬盘,超过2T的硬盘将只能用2T空间(有第三方解决方法)
GPT(GUID Partition Table)
GUID磁盘分区表(GUID Partition Table,缩写:GPT)其含义为"全局唯一标识磁盘分区表",是一个实体硬盘的分区表的结构布局的标准。它是可扩展固件接口(EFI)标准(被Intel用于替代个人计算机的BIOS)的一部分,被用于替代BIOS系统中的一32bits来存储逻辑块地址和大小信息的主开机纪录(MBR)分区表。
全局唯一标识分区表,是一个较新的分区机制,解决了MBR很多缺点。
支持超过2T的磁盘(64位寻址空间)。fdisk最大只能建立2TB大小的分区,创建一个大于2TB的分区使用parted。
向后兼容MBR。
必须在支持UEFI的硬件上才能使用(Intel提出,用于取代BIOS)
必须使用64位系统。
Mac、Linux系统都能支持GPT分区格式。
Windows 7/8 64bit、Windows Server 2008 64bit支持GPT。
以上就是Linux系统MBR和GPT分区的区别,总得来说GPT比MBR更先进,但是MBR的兼容性比GPT要好。
parted命令是由GNU组织开发的一款功能强大的磁盘分区和分区大小调整工具,与fdisk不同,它支持调整分区的大小。作为一种设计用于Linux的工具,它没有构建成处理与fdisk关联的多种分区类型,但是,它可以处理最常见的分区格式,包括:ext2、ext3、fat16、fat32、NTFS、ReiserFS、JFS、XFS、UFS、HFS以及Linux交换分区。
用法:parted [选项]… [设备 [命令 [参数]…]…]
将带有"参数"的命令应用于"设备"。如果没有给出"命令",则以交互模式运行
cp [FROM-DEVICE] FROM-MINOR TO-MINOR //将文件系统复制到另一个分区
help [COMMAND] //打印通用求助信息,或关于 COMMAND 的信息
mkfs MINOR 文件系统类型 //在 MINOR 创建类型为"文件系统类型"的文件系统
mkpart 分区类型 [文件系统类型] 起始点 终止点 //创建一个分区
mkpartfs 分区类型 文件系统类型 起始点 终止点 //创建一个带有文件系统的分区
move MINOR 起始点 终止点 //移动编号为 MINOR 的分区
name MINOR 名称 //将编号为 MINOR 的分区命名为"名称"
rescue 起始点 终止点 //挽救临近"起始点"、"终止点"的遗失的分区
resize MINOR 起始点 终止点 //改变位于编号为 MINOR 的分区中文件系统的大小
set MINOR 标志 状态 //改变编号为 MINOR 的分区的标志
操作实例
如出现command not found,执行以下命令安装
[root@localhost ~]# yum -y install parted

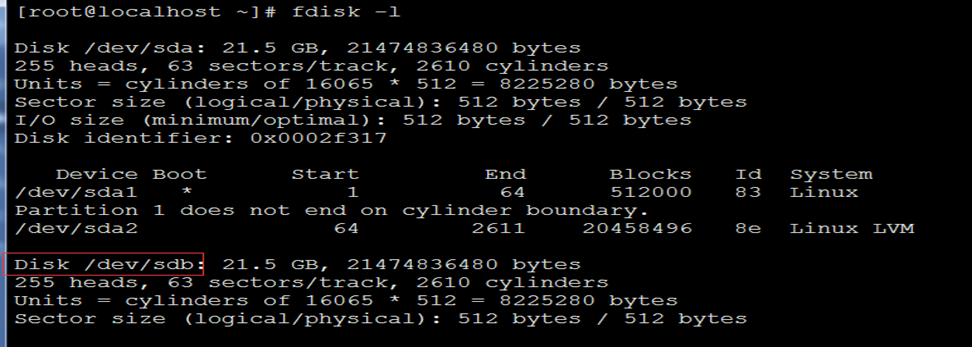
1)首先类似fdisk一样,先选择要分区的硬盘,此处为/dev/sdb

2)选择了/dev/sdb作为我们操作的磁盘,接下来需要创建一个分区表(在parted中可以使用help命令打印帮助信息):
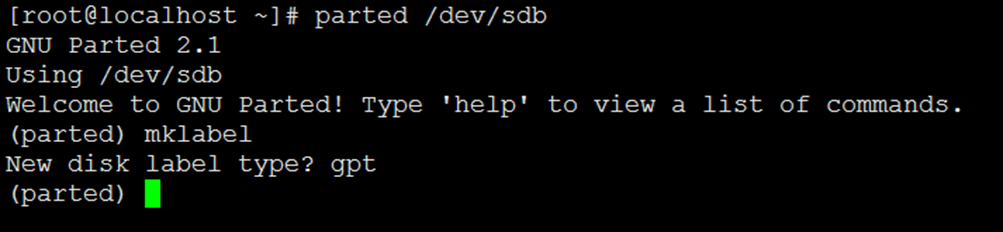
(parted) mklabel
New disk label type? (我们要正确分区大于2TB的磁盘,应该使用gpt方式的分区表,输入gpt后回车)gpt
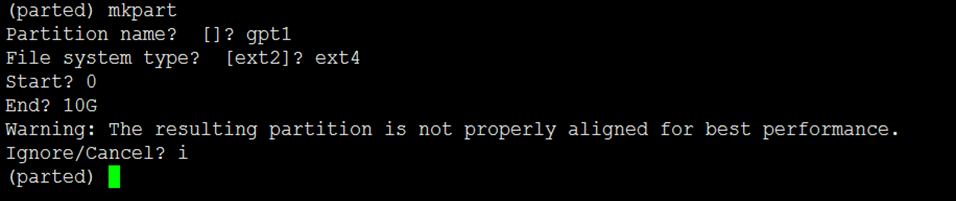
3)创建好分区表以后,接下来就可以进行分区操作了,执行mkpart命令,分别输入分区名称,文件系统和分区 的起止位置
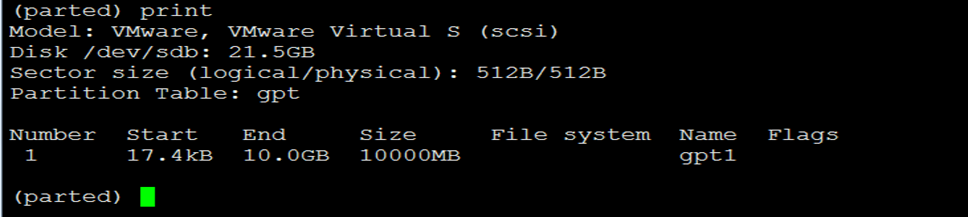
4)分好区后可以使用print命令打印分区信息,下面是一个print的样例
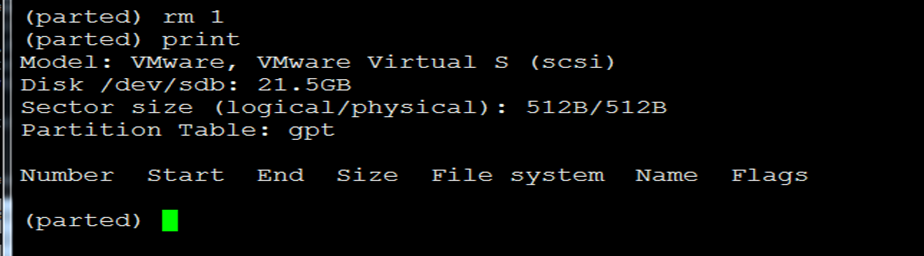
5)如果分区写错了,可以使用rm命令删除分区,比如我们要删除上面的分区,然后打印删除后的结果
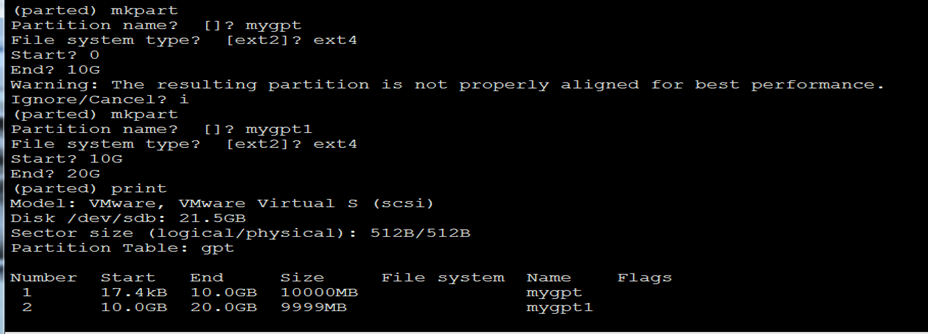
6)按照上面的方法把整个硬盘都分好区,下面是一个分完后的样例
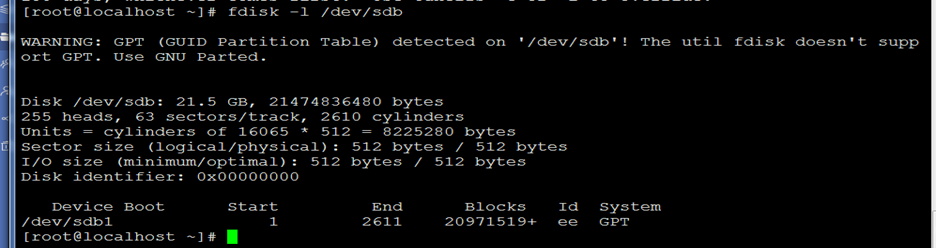
7)由于parted内建的mkfs还不够完善,所以完成以后我们可以使用quit命令退出parted并使用 系统的mkfs命令对分区进行格式化了,此时如果使用fdisk -l命令打印分区表会出现警告信息,这是正常的
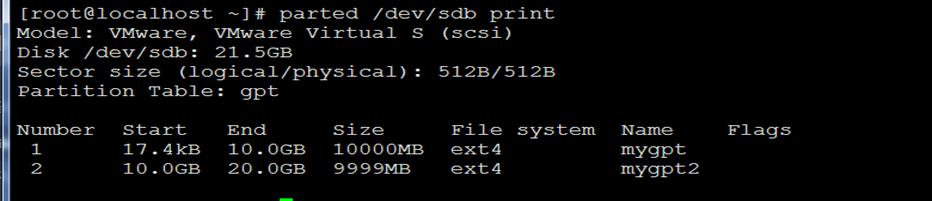
8)我们发现此时并不能查看到我们刚才的分区信息。因为使用fdisk工具无法查看gpt分区类型的详细信息。只能查看msdos类型的分区信息(即MBR分区)。那么怎么查看呢?还是要使用parted工具。你可以直接键入命令"parted /dev/sdb print".如下:
9)格式化
[root@localhost ~]# mkfs.ext4 /dev/sdb1
[root@localhost ~]# mkfs.ext4 /dev/sdb2
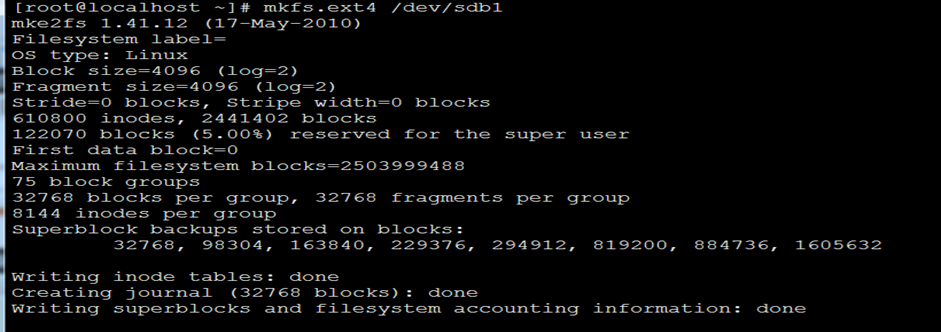
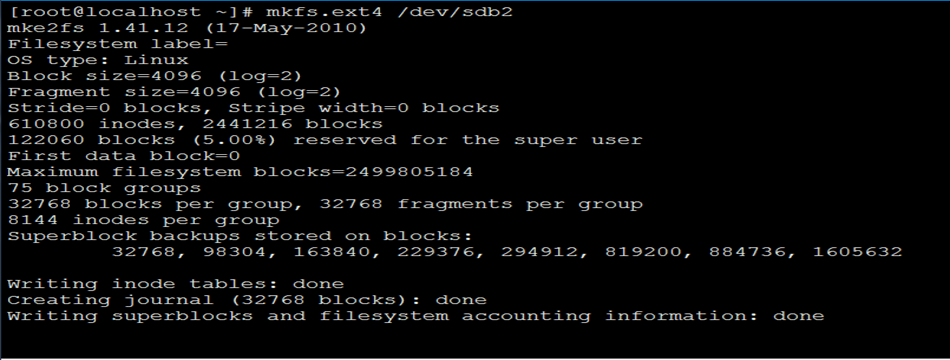
10)挂载:
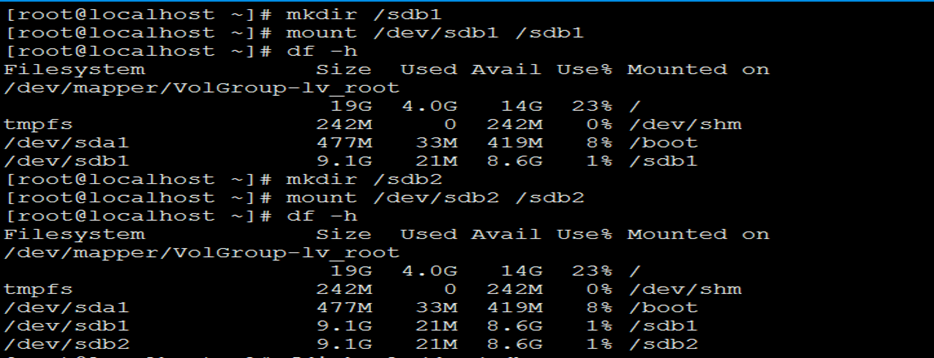
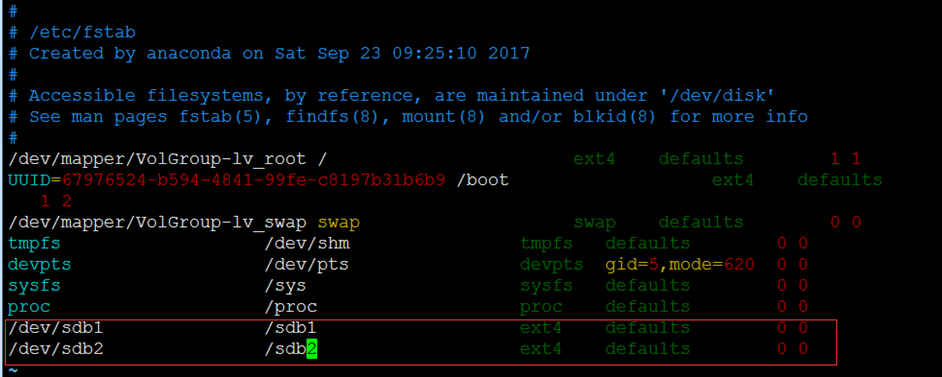
11)添加到/etc/fstab
若文章图片、下载链接等信息出错,请在评论区留言反馈,博主将第一时间更新!如本文“对您有用”,欢迎随意打赏,谢谢!


亲测,写的不错,感谢博主