
一、Hadoop简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),其中一个组件是HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
二、Hadoop优点
Hadoop是一个能够对大量数据进行分布式处理的软件框架。 Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。
Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。
Hadoop 还是可伸缩的,能够处理PB级数据。
此外,Hadoop 依赖于社区服务,因此它的成本比较低,任何人都可以使用。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点:
- 高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖 。
- 高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
- 高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快 。
- 高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配 。
- 低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
Hadoop带有用Java语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。Hadoop上的应用程序也可以使用其他语言编写,比如C++。
1、系统准备
操作系统:CentOS Linux release 7.8.2003
2、软件版本
hadoop:hadoop-2.7.2.tar.gz
JDK:jdk-8u181-linux-x64.tar.gz
3、集群规划
|
节点名称 |
操作系统 |
IP地址 |
|
master |
CentOS Linux release 7.8.2003 |
172.168.1.157 |
|
node1 |
CentOS Linux release 7.8.2003 |
172.168.1.158 |
|
node2 |
CentOS Linux release 7.8.2003 |
172.168.1.159 |
三、JAVA环境部署
1、安装包准备
版本:jdk-8u181
下载地址:https://www.oracle.com/technetwork/java/javase/downloads/java-archive-javase8-2177648.html
2、安装步骤
1)解压JDK软件包
[root@localhost ~]# tar zxf jdk-8u181-linux-x64.tar.gz -C /usr/local
2)配置系统环境变量
[root@localhost ~]# vim /etc/profile
# 加入以下内容
export JAVA_HOME=/usr/local/jdk1.8.0_181
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH:$HOMR/bin
执行source /etc/profile使其生效
3)使用java、javac等命令验证是否安装成功
[root@master ~]# java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
四、Hadoop安装
1)配置主机名(所有节点)
[root@localhost ~]# hostnamectl set-hostname master
[root@localhost ~]# hostnamectl set-hostname node1
[root@localhost ~]# hostnamectl set-hostname node2
2)配置hosts文件
[root@master ~]# vim /etc/hosts
# 添加以下内容
172.168.1.157 master
172.168.1.158 node1
172.168.1.159 node2
3)配置免密钥
[root@master ~]# ssh-keygen
# 输入三次确定
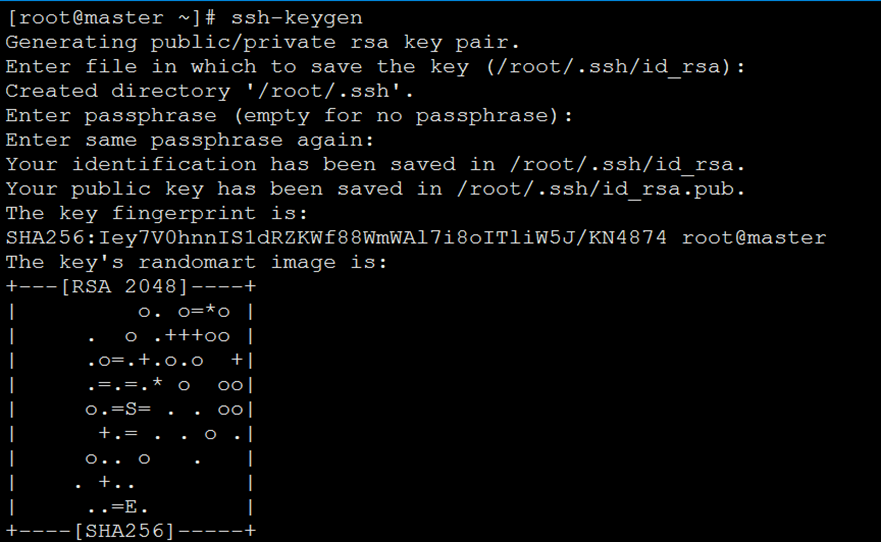
[root@master ~]# ssh-copy-id root@master
[root@master ~]# ssh-copy-id root@node1
[root@master ~]# ssh-copy-id root@node2
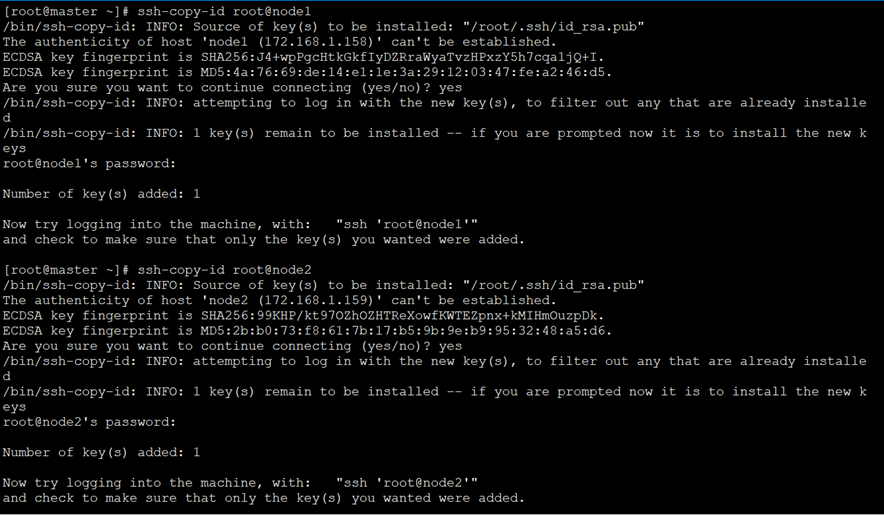
4)拷贝hosts文件到各节点
[root@master ~]# scp /etc/hosts root@node1:/etc/
[root@master ~]# scp /etc/hosts root@node2:/etc/
5)下载Hadoop
[root@master ~]# wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/hadoop-2.7.2.tar.gz
6)解压
[root@master ~]# tar xf hadoop-2.7.2.tar.gz -C /usr/local
7)配置环境变量
[root@master ~]# vim /etc/profile
# 加入以下内容
export Hadoop_Home=/usr/local/hadoop-2.7.2
export PATH=$PATH:$Hadoop_Home/bin
[root@master ~]# source /etc/profile
8)拷贝/etc/profile文件到各节点
[root@master ~]# scp /etc/profile root@node1:/etc/
[root@master ~]# scp /etc/profile root@node2:/etc/
五、Hadoop配置
1)配置hadoop-env.sh
[root@master ~]# cd /usr/local/hadoop-2.7.2/etc/hadoop/
[root@master hadoop]# vim hadoop-env.sh
# 加入以下内容
export JAVA_HOME=/usr/local/jdk1.8.0_181
export HADOOP_PREFIX=/usr/local/hadoop-2.7.2
2)配置yarn-env.sh
[root@master hadoop]# sed -i '/HADOOP_YARN_USER/iexport JAVA_HOME=/usr/local/jdk1.8.0_181/' yarn-env.sh
3)配置core-site.xml
[root@master hadoop]# mkdir /usr/local/hadoop-2.7.2/tmp
[root@master hadoop]# vim core-site.xml
# 加入以下内容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/mnt/hadoop/tmp</value>
</property>
</configuration>
4)配置hdfs-site.xml
[root@master hadoop]# vim hdfs-site.xml
# 加入以下内容
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/mnt/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/mnt/hadoop/dfs/data</value>
</property>
</configuration>
5)配置mapred-site.xml
[root@master hadoop]# vim mapred-site.xml
# 加入以下内容
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
6)配置yarn-site.xml
[root@master hadoop]# vim yarn-site.xml
# 加入以下内容
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
7)配置slaves
[root@master hadoop]# vim slaves
# 加入以下内容
master
node1
node2
[root@master hadoop]# scp -r /usr/local/hadoop-2.7.2/ root@node2:/usr/local
[root@master hadoop]# scp -r /usr/local/hadoop-2.7.2/ root@node1:/usr/local
9)在slave节点执行source /etc/profile
[root@node1 ~]# source /etc/profile
[root@node2 ~]# source /etc/profile
六、Hadoop使用
1)格式化NameNode
# Master节点上,执行如下命令
[root@master hadoop]# hdfs namenode -format
2)启动HDFS(NameNode、DataNode)
# Master节点上,执行如下命令
[root@master hadoop]# cd ../../sbin
[root@master sbin]# ./start-dfs.sh
Starting namenodes on [master]
master: starting namenode, logging to /usr/local/hadoop-2.7.2/logs/hadoop-root-namenode-master.out
node1: starting datanode, logging to /usr/local/hadoop-2.7.2/logs/hadoop-root-datanode-node1.out
master: starting datanode, logging to /usr/local/hadoop-2.7.2/logs/hadoop-root-datanode-master.out
node2: starting datanode, logging to /usr/local/hadoop-2.7.2/logs/hadoop-root-datanode-node2.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop-2.7.2/logs/hadoop-root-secondarynamenode-master.out
3)使用jps命令查看进程(所有节点)
[root@master sbin]# jps
3267 NameNode
3403 DataNode
3581 SecondaryNameNode
3726 Jps
[root@node1 ~]# jps
1799 DataNode
1882 Jps
[root@node2 ~]# jps
2837 DataNode
2921 Jps
4)启动 Yarn(ResourceManager 、NodeManager)
[root@master sbin]# ./start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop-2.7.2/logs/yarn-root-resourcemanager-master.out
node1: starting nodemanager, logging to /usr/local/hadoop-2.7.2/logs/yarn-root-nodemanager-node1.out
master: starting nodemanager, logging to /usr/local/hadoop-2.7.2/logs/yarn-root-nodemanager-master.out
node2: starting nodemanager, logging to /usr/local/hadoop-2.7.2/logs/yarn-root-nodemanager-node2.out
5)使用jps命令查看进程(所有节点)
[root@master sbin]# jps
3267 NameNode
4211 Jps
3892 NodeManager
3786 ResourceManager
3403 DataNode
3581 SecondaryNameNode
[root@node1 ~]# jps
2050 Jps
1799 DataNode
1927 NodeManager
[root@node2 ~]# jps
2837 DataNode
3173 Jps
3050 NodeManager
6)查看HDFS信息
# 浏览器输入http://172.168.1.157:50070
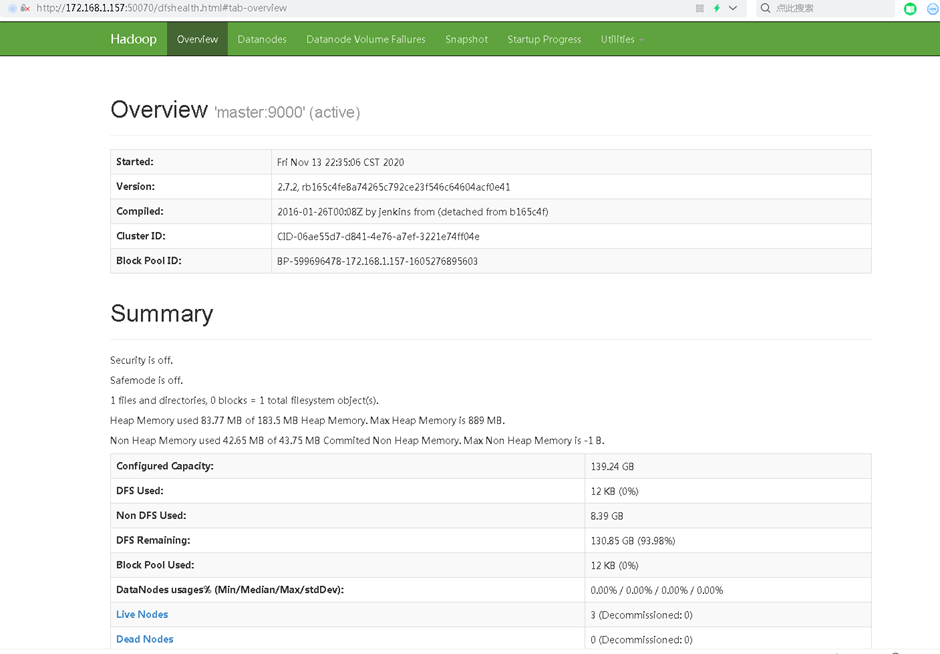
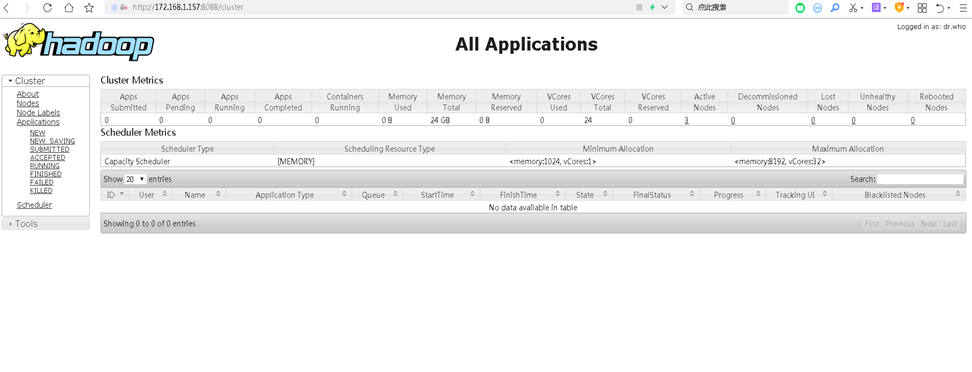
7)查看Yarn信息
# 浏览器输入http://172.168.1.157:8088
8)停止Yarn及HDFS
[root@master sbin]# ./stop-yarn.sh
[root@master sbin]# ./stop-dfs.sh
至此,Hadoop分布式集群搭建完毕。
若文章图片、下载链接等信息出错,请在评论区留言反馈,博主将第一时间更新!如本文“对您有用”,欢迎随意打赏,谢谢!


评论