
一、Zookeeper简介
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
二、Kafka简介
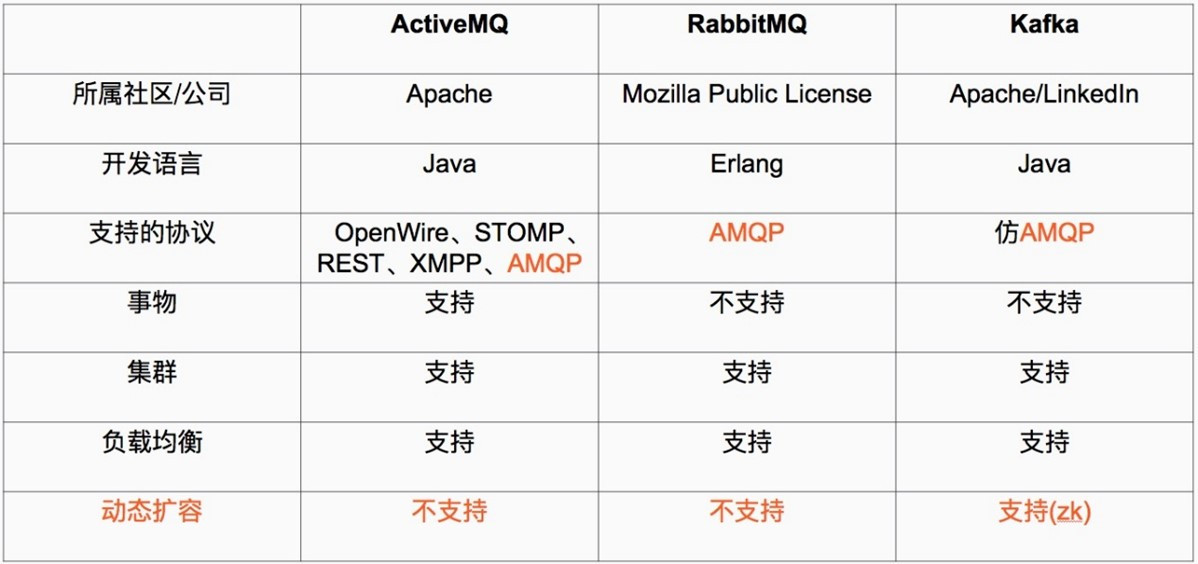
Kafka 被称为下一代分布式-订阅消息系统,是非营利性组织ASF(Apache Software Foundation,简称为ASF)基金会中的一个开源项目,比如HTTP Server、Hadoop、ActiveMQ、Tomcat等开源软件都属于Apache基金会的开源软件,类似的消息系统还有RbbitMQ、ActiveMQ、ZeroMQ,最主要的优势是其具备分布式功能、并且结合zookeeper可以实现动态扩容。
Apache Kafka 与传统消息系统相比,有以下不同:
1)它被设计为一个分布式系统,易于向外扩展;
2)它同时为发布和订阅提供高吞吐量;
3)它支持多订阅者,当失败时能自动平衡消费者;
4)它将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。
三、Zookeeper+Kafka集群部署
1、部署环境
|
序号 |
IP地址 |
主机名 |
安装软件 |
|
1 |
192.168.8.35 |
server1 |
JDK、Zookeeper、Kafka |
|
2 |
192.168.8.36 |
server2 |
JDK、Zookeeper、Kafka |
|
3 |
192.168.8.37 |
server3 |
JDK、Zookeeper、Kafka |
1)修改主机名
[root@server1 ~]# hostnamectl set-hostname server1
[root@server1 ~]# hostnamectl set-hostname server2
[root@server1 ~]# hostnamectl set-hostname server3
2)配置hosts
# 三台服务器分别配置hosts文件
[root@server1 ~]# vim /etc/hosts
192.168.8.35 server1
192.168.8.36 server2
192.168.8.37 server3
2、安装JDK
JDK下载地址:https://www.oracle.com/java/technologies/javase/javase8-archive-downloads.html
注:3台机器都需要安装
1)安装JDK-1.8
[root@server1 ~]# yum -y install jdk-8u351-linux-x64.rpm
2)查看是否安装成功
[root@server1 ~]# java -version
java version "1.8.0_351"
Java(TM) SE Runtime Environment (build 1.8.0_351-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.351-b10, mixed mode)
3、安装Zookeeper
# 在192.168.8.35(server1)操作
1)下载zookeeper安装包
[root@server1 ~]# wget -c https://dlcdn.apache.org/zookeeper/zookeeper-3.7.1/apache-zookeeper-3.7.1-bin.tar.gz
2)解压并重命名
[root@server1 ~]# tar xf apache-zookeeper-3.7.1-bin.tar.gz
[root@server1 ~]# mv apache-zookeeper-3.7.1-bin /usr/local/zookeeper
3)创建快照日志存放目录和事务日志存放目录
[root@server1 ~]# mkdir -p /usr/local/zookeeper/{data,logs}
注:如果不配置dataLogDir,那么事务日志也会写在data目录中。这样会严重影响zookeeper的性能。因为在zookeeper吞吐量很高的时候,产生的事务日志和快照日志太多。
[root@server1 ~]# cd /usr/local/zookeeper/conf
[root@server1 conf]# cp zoo_sample.cfg zoo.cfg
[root@server1 conf]# vim zoo.cfg
# 服务器之间或客户端与服务器之间的单次心跳检测时间间隔,单位为毫秒
tickTime=2000
# 集群中leader服务器与follower服务器第一次连接最多次数
initLimit=10
# 集群中leader服务器与follower服务器第一次连接最多次数
syncLimit=5
# 客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求
clientPort=2181
# 存放数据文件
dataDir=/usr/local/zookeeper/data
# 存放日志文件
dataLogDir=/usr/local/zookeeper/logs
#Zookeeper cluster,2888为选举端口,3888为心跳端口
# 服务器编号=服务器IP:LF数据同步端口:LF选举端口
server.1=server1:2888:3888
server.2=server2:2888:3888
server.3=server3:2888:3888
[root@server1 conf]# echo "1" > /usr/local/zookeeper/data/myid
4)配置系统服务
[root@server1 conf]# vim /etc/systemd/system/zookeeper.service
[Unit]
Description=Zookeeper Server
After=network-online.target remote-fs.target nss-lookup.target
Wants=network-online.target
[Service]
Type=forking
ExecStart=/usr/local/zookeeper/bin/zkServer.sh start
ExecStop=/usr/local/zookeeper/bin/zkServer.sh stop
User=root
Group=root
[Install]
WantedBy=multi-user.target
5)启动Zookeeper
[root@server1 conf]# systemctl daemon-reload
[root@server1 conf]# systemctl start zookeeper
[root@server1 conf]# systemctl enable zookeeper
# 在192.168.8.36(server2)操作
1)下载zookeeper安装包
[root@server2 ~]# wget -c https://dlcdn.apache.org/zookeeper/zookeeper-3.7.1/apache-zookeeper-3.7.1-bin.tar.gz
2)解压并重命名
[root@server2 ~]# tar xf apache-zookeeper-3.7.1-bin.tar.gz
[root@server2 ~]# mv apache-zookeeper-3.7.1-bin /usr/local/zookeeper
3)创建快照日志存放目录和事务日志存放目录
[root@server2 ~]# mkdir -p /usr/local/zookeeper/{data,logs}
注:如果不配置dataLogDir,那么事务日志也会写在data目录中。这样会严重影响zookeeper的性能。因为在zookeeper吞吐量很高的时候,产生的事务日志和快照日志太多。
[root@server2 ~]# cd /usr/local/zookeeper/conf
[root@server2 conf]# cp zoo_sample.cfg zoo.cfg
[root@server2 conf]# vim zoo.cfg
# 服务器之间或客户端与服务器之间的单次心跳检测时间间隔,单位为毫秒
tickTime=2000
# 集群中leader服务器与follower服务器第一次连接最多次数
initLimit=10
# 集群中leader服务器与follower服务器第一次连接最多次数
syncLimit=5
# 客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求
clientPort=2181
# 存放数据文件
dataDir=/usr/local/zookeeper/data
# 存放日志文件
dataLogDir=/usr/local/zookeeper/logs
#Zookeeper cluster,2888为选举端口,3888为心跳端口
# 服务器编号=服务器IP:LF数据同步端口:LF选举端口
server.1=server1:2888:3888
server.2=server2:2888:3888
server.3=server3:2888:3888
[root@server2 conf]# echo "2" > /usr/local/zookeeper/data/myid
4)配置系统服务
[root@server2 conf]# vim /etc/systemd/system/zookeeper.service
[Unit]
Description=Zookeeper Server
After=network-online.target remote-fs.target nss-lookup.target
Wants=network-online.target
[Service]
Type=forking
ExecStart=/usr/local/zookeeper/bin/zkServer.sh start
ExecStop=/usr/local/zookeeper/bin/zkServer.sh stop
User=root
Group=root
[Install]
WantedBy=multi-user.target
5)启动Zookeeper
[root@server2 conf]# systemctl daemon-reload
[root@server2 conf]# systemctl start zookeeper
[root@server2 conf]# systemctl enable zookeeper
# 在192.168.8.37(server3)操作
1)下载zookeeper安装包
[root@server3 ~]# wget -c https://dlcdn.apache.org/zookeeper/zookeeper-3.7.1/apache-zookeeper-3.7.1-bin.tar.gz
2)解压并重命名
[root@server3 ~]# tar xf apache-zookeeper-3.7.1-bin.tar.gz
[root@server3 ~]# mv apache-zookeeper-3.7.1-bin /usr/local/zookeeper
3)创建快照日志存放目录和事务日志存放目录
[root@server3 ~]# mkdir -p /usr/local/zookeeper/{data,logs}
注:如果不配置dataLogDir,那么事务日志也会写在data目录中。这样会严重影响zookeeper的性能。因为在zookeeper吞吐量很高的时候,产生的事务日志和快照日志太多。
[root@server3 ~]# cd /usr/local/zookeeper/conf
[root@server3 conf]# cp zoo_sample.cfg zoo.cfg
[root@server3 conf]# vim zoo.cfg
# 服务器之间或客户端与服务器之间的单次心跳检测时间间隔,单位为毫秒
tickTime=2000
# 集群中leader服务器与follower服务器第一次连接最多次数
initLimit=10
# 集群中leader服务器与follower服务器第一次连接最多次数
syncLimit=5
# 客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求
clientPort=2181
# 存放数据文件
dataDir=/usr/local/zookeeper/data
# 存放日志文件
dataLogDir=/usr/local/zookeeper/logs
#Zookeeper cluster,2888为选举端口,3888为心跳端口
# 服务器编号=服务器IP:LF数据同步端口:LF选举端口
server.1=server1:2888:3888
server.2=server2:2888:3888
server.3=server3:2888:3888
[root@server3 conf]# echo "3" > /usr/local/zookeeper/data/myid
4)配置系统服务
[root@server3 conf]# vim /etc/systemd/system/zookeeper.service
[Unit]
Description=Zookeeper Server
After=network-online.target remote-fs.target nss-lookup.target
Wants=network-online.target
[Service]
Type=forking
ExecStart=/usr/local/zookeeper/bin/zkServer.sh start
ExecStop=/usr/local/zookeeper/bin/zkServer.sh stop
User=root
Group=root
[Install]
WantedBy=multi-user.target
5)启动Zookeeper
[root@server3 conf]# systemctl daemon-reload
[root@server3 conf]# systemctl start zookeeper
[root@server3 conf]# systemctl enable zookeeper
6)查看Zookeeper状态
[root@server1 conf]# /usr/local/zookeeper/bin/zkServer.sh status
/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@server2 conf]# /usr/local/zookeeper/bin/zkServer.sh status
/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
[root@server3 conf]# /usr/local/zookeeper/bin/zkServer.sh status
/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
4、安装Kafka
# 在192.168.8.35(server1)操作
1)下载安装包
[root@server1 conf]# cd ~ && wget -c https://archive.apache.org/dist/kafka/3.2.1/kafka_2.13-3.2.1.tgz
2)解压并重命名
[root@server1 ~]# tar xf kafka_2.13-3.2.1.tgz
[root@server1 ~]# mv kafka_2.13-3.2.1 /usr/local/kafka
3)配置server.properties
[root@server1 ~]# vim /usr/local/kafka/config/server.properties
broker.id=1
listeners=PLAINTEXT://server1:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/usr/local/kafka/logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=server1:2181,server2:2181,server3:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
delete.topic.enable=true
auto.create.topics.enable=true
4)配置系统服务
[root@server1 ~]# vim /etc/systemd/system/kafka.service
[Unit]
Description=Kafka Server
After=network-online.target remote-fs.target nss-lookup.target
Wants=network-online.target
[Service]
Type=forking
ExecStart=/usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh
User=root
Group=root
[Install]
WantedBy=multi-user.target
5)启动Kafka
[root@server1 ~]# systemctl daemon-reload
[root@server1 ~]# systemctl start kafka
[root@server1 ~]# systemctl enable kafka
# 在192.168.8.36(server2)操作
1)下载安装包
[root@server1 conf]# cd ~ && wget -c https://archive.apache.org/dist/kafka/3.2.1/kafka_2.13-3.2.1.tgz
2)解压并重命名
[root@server2 ~]# tar xf kafka_2.13-3.2.1.tgz
[root@server2 ~]# mv kafka_2.13-3.2.1 /usr/local/kafka
3)配置server.properties
[root@server2 ~]# vim /usr/local/kafka/config/server.properties
broker.id=2
listeners=PLAINTEXT://server2:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/usr/local/kafka/logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=server1:2181,server2:2181,server3:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
delete.topic.enable=true
auto.create.topics.enable=true
4)配置系统服务
[root@server2 ~]# vim /etc/systemd/system/kafka.service
[Unit]
Description=Kafka Server
After=network-online.target remote-fs.target nss-lookup.target
Wants=network-online.target
[Service]
Type=forking
ExecStart=/usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh
User=root
Group=root
[Install]
WantedBy=multi-user.target
5)启动Kafka
[root@server2 ~]# systemctl daemon-reload
[root@server2 ~]# systemctl start kafka
[root@server2 ~]# systemctl enable kafka
# 在192.168.8.37(server3)操作
1)下载安装包
[root@server3 conf]# cd ~ && wget -c https://archive.apache.org/dist/kafka/3.2.1/kafka_2.13-3.2.1.tgz
2)解压并重命名
[root@server3 ~]# tar xf kafka_2.13-3.2.1.tgz
[root@server3 ~]# mv kafka_2.13-3.2.1 /usr/local/kafka
3)配置server.properties
[root@server3 ~]# vim /usr/local/kafka/config/server.properties
broker.id=3
listeners=PLAINTEXT://server3:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/usr/local/kafka/logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=server1:2181,server2:2181,server3:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
delete.topic.enable=true
auto.create.topics.enable=true
4)配置系统服务
[root@server3 ~]# vim /etc/systemd/system/kafka.service
[Unit]
Description=Kafka Server
After=network-online.target remote-fs.target nss-lookup.target
Wants=network-online.target
[Service]
Type=forking
ExecStart=/usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh
User=root
Group=root
[Install]
WantedBy=multi-user.target
5)启动Kafka
[root@server3 ~]# systemctl daemon-reload
[root@server3 ~]# systemctl start kafka
[root@server3 ~]# systemctl enable kafka
5、测试Kafka数据消费
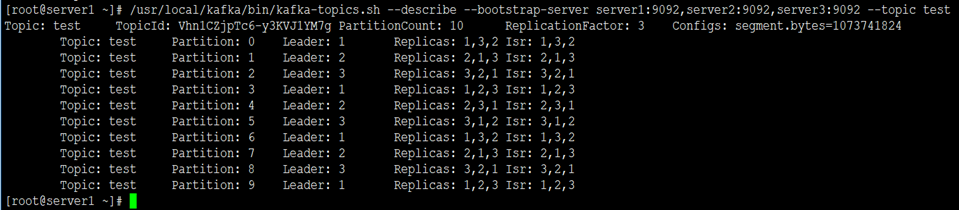
1)创建topic
# 创建名为test,partitions(分区)为10,replication(副本)为3的topic
[root@server1 ~]# /usr/local/kafka/bin/kafka-topics.sh --create --bootstrap-server server1:9092,server2:9092,server3:9092 --partitions 10 --replication-factor 3 --topic test
Created topic test.
2)获取topic
[root@server1 ~]# /usr/local/kafka/bin/kafka-topics.sh --describe --bootstrap-server server1:9092,server2:9092,server3:9092 --topic test
3)获取所有topic
[root@server1 ~]# /usr/local/kafka/bin/kafka-topics.sh --list --bootstrap-server server1:9092,server2:9092,server3:9092
test
4)删除topic
[root@server1 ~]# /usr/local/kafka/bin/kafka-topics.sh --delete --bootstrap-server server1:9092,server2:9092,server3:9092 --topic test
5)kafka命令测试消息发送
1、创建topic
[root@server1 ~]# /usr/local/kafka/bin/kafka-topics.sh --create --bootstrap-server server1:9092,server2:9092,server3:9092 --partitions 10 --replication-factor 3 --topic test
Created topic test.
2、发送消息
[root@server1 ~]# /usr/local/kafka/bin/kafka-console-producer.sh --broker-list server1:9092,server2:9092,server3:9092 --topic test
>hello
>world
>linux
3、获取数据
[root@server2 ~]# /usr/local/kafka/bin/kafka-console-consumer.sh --bootstrap-server server1:9092,server2:9092,server3:9092 --topic test --from-beginning
hello
world
linux
[root@server3 ~]# /usr/local/kafka/bin/kafka-console-consumer.sh --bootstrap-server server1:9092,server2:9092,server3:9092 --topic test --from-beginning
hello
world
linux
结果:生产者可正常生产数据,消费者能消费到数据。
若文章图片、下载链接等信息出错,请在评论区留言反馈,博主将第一时间更新!如本文“对您有用”,欢迎随意打赏,谢谢!


评论